
함수형 자바스크립트 스터디 내용정리 (Chapter3)
본 포스트의 내용은 FUNCTIONAL PROGRAMMING IN JAVASCRIPT (함수형 자바스크립트) 교재의 스터디 내용을 기반으로 작성하였습니다
이 장의 내용
- 자료구조를 순차적으로 탐색/변환하는 데 쓰이는 실용적인 연산들(map, reduce, filter)
- 로대시JS
- 함수형 프로그래밍에서 재귀의 중요성
3.1 애플리케이션의 제어 흐름
프로그램이 정답에 이르기까지 거치는 경로를 제어흐름(control flow)이라고 합니다. 명령형 프로그램은 작업 수행에 필요한 전 단계를 노출하여 흐름이나 경로를 아주 자세히 서술합니다. 명령형 프로그램의 틀을 고수준에서 바라보면 다음 코드와 같습니다.
- javascript
1 | var loop = opt(); |
[그림 3-1]은 간단히 표현한 프로그램의 흐름도입니다.
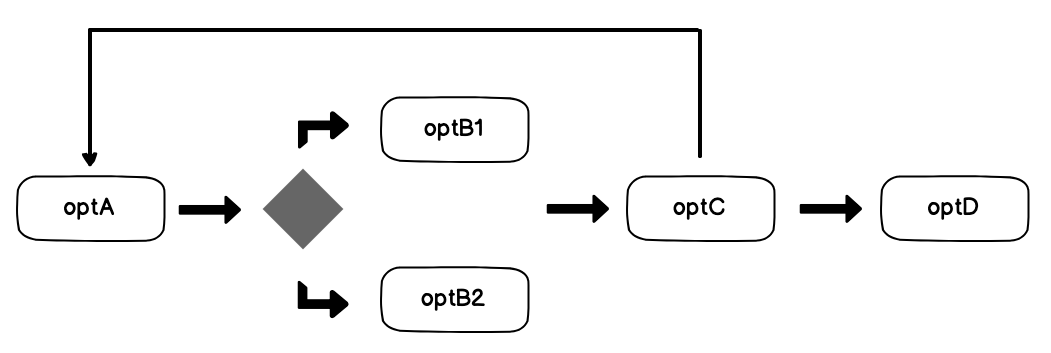 그림3-1 명령형 프로그램은 분기, 루프에 따라 움직이는 일련의 연산(구문)들로 구성됩니다.
그림3-1 명령형 프로그램은 분기, 루프에 따라 움직이는 일련의 연산(구문)들로 구성됩니다.반면 선언적 프로그램, 특히 함수형 프로그램은 독립적인 블랙박스 연산들이 단순하게, 즉 최소한의 제어구조를 통해 연결되어 추상화 수준이 높습니다. 이렇게 연결한 연산들은 각자 다음 연산으로 상태를 이동시키는 고계함수에 불과합니다. 실제로 함수형 프로그램은 데이터와 제어 흐름 자체를 고수준 컴포넌트 사이의 단순한 연결로 취급합니다.
 그림3-2 함수형 프로그램은 서로 연결된 블랙박스 연산을 제어합니다. 정보는 한 연산에서 다른 연산으로 독립적으로 흘러가며, 분기와 반복은 상당 부분 줄이거나 아예 없애고 고수준의 추상화로 대체합니다.
그림3-2 함수형 프로그램은 서로 연결된 블랙박스 연산을 제어합니다. 정보는 한 연산에서 다른 연산으로 독립적으로 흘러가며, 분기와 반복은 상당 부분 줄이거나 아예 없애고 고수준의 추상화로 대체합니다.덕분에 다음과 같이 코드가 짧아집니다.1
optA().optB().optC().optD(); //점으로 연결하려면 이들 메서드가 모두 포함된 공유 객체가 있어야 합니다.
3.2 메서드 체이닝
메서드 체이닝(method chaining)은 여러 메서드를 단일 구문으로 호출하는 OOP패턴입니다. 메서드가 모두 동일한 객체에 속해 있으면 메서드 흘리기(method cascading)라고도 합니다. 대부분 객체지향 프로그램에서 불변 객체에 많이 적용하는 패턴이지만 함수형 프로그래밍에도 잘 맞습니다. 문자열을 다루는 예제 하나를 봅시다.
1 | concat(toLowerCase(substring('Functional Programming', 1, 10)), ' is fun'); |
매개변수는 모두 함수 선언부에 명시해서 부수효과를 없애고 원본 객체를 바꾸지 않아야 한다는 함수형 교리를 충실히 반영한 코드입니다. 그러나 이렇게 함수 코드를 안쪽에서 바깥쪽으로 작성하면 메서드 체이닝 방식만큼 매끄럽지 못합니다. 로직을 파악하려면 가장 안쪽에 감싼 함수부터 한 꺼풀씩 벗겨내야 하고 가독성도 현저히 떨어지지요.
변이를 일으키지 않는 한 함수형 프로그래밍에서도 단일 객체 인스턴스에 속한 메서드를 체이닝하는 건 나름대로 쓸모가 있습니다. 자바스크립트 배열에도 문자열 객체에 메서드를 체이닝하는 패턴을 확장시켜 적용할 수는 있지만, 안타깝게도 많은 사람이 익숙하지 않은 탓에 머릿속에 떠오르는 지저분한 루프를 다시 꺼내 쓰기 쉽습니다.
3.3 함수 체이닝
객체지향 프로그램은 주로 상속을 통해 코드를 재사용합니다. 순수 객체지향 언어에서, 특히 언어 자체의 자료구조를 구현한 코드를 보면 이런 패턴이 자주 눈에 띕니다. 가령 자바에는 List 인터페이스를 용도에 맞게 구현한 ArrayList, LinkedList, DoublyLinkedList, CopyOnWriteArrayList 등이 있습니다. 이들은 모두 한 부모에서 출발하여 나름대로 특수한 기능을 덧붙인 클래스입니다.
FP는 접근 방법이 다릅니다. 자료구조를 새로 만들어 어떤 요건을 충족시키는게 아니라, 배열 등의 흔한 자료구조를 이용해 다수의 굵게 나뉜 고계 연산을 적용합니다. 이러한 고계 연산으로 다음과 같은 일을 합니다.
작업을 수행하기 위해 무슨 일을 해야 하는지 기술된 함수를 인수로 받습니다.
임시 변수의 값을 계속 바꾸면서 부수효과를 일으키는 기존 수동 루프를 대체합니다. 그 결과 관리할 코드가 줄고 에러가 날 만한 코드 역시 줄어듭니다.
좀 더 자세히 살펴보기 위해 Person 객체의 컬렉션을 기준으로 테스트 객체를 만들어 보겠습니다.
1 | const p1 = new Person('Haskell', 'Curry', '111-11-1111'); |
3.3.1 람다 표현식
함수형 프로그래밍에서 탄생한 람다 표현식(lamda expression) (자바스크립트에서는 두 줄 화살표 함수(fat-arrow function) 라고도 함)은 한 줄짜리 익명 함수를 일반 함수 선언보다 단축된 구문으로 나타냅니다. 람다 함수는 여러 줄로도 표기할 수 있지만, 2장에서 보았듯이 거의 대부분 한 줄로 씁니다. 사람 이름을 추출하는 간단한 예제를 봅시다.1
2const name = p => p.fullname;
console.log(name(p1)); //-> 'Haskell Curry'
(p) => p.fullname은 매개변수 p를 받아 p.fullname을 반환하는 간편 구문입니다. 자세한 구문 구조는 [그림 3-3]을 참고하세요
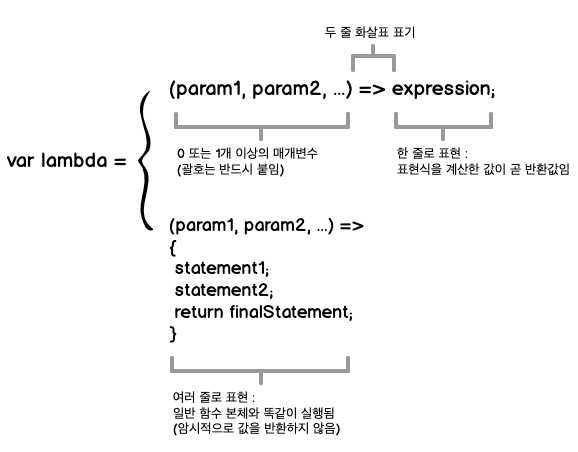 그림3-3 화살표 함수의 해부도. 람다 함수 우변에는 단일 표현식이나 여러 구문이 포함된 블록이 옵니다.
그림3-3 화살표 함수의 해부도. 람다 함수 우변에는 단일 표현식이나 여러 구문이 포함된 블록이 옵니다.람다 표현식은 항상 어떤 값을 반환하게 만들어 함수 정의부를 확실히 함수형으로 굳힙니다. 한 줄짜리 표현식의 반환값은 함수 본체를 실행한 결과값입니다. 여기서 주목할 점은 일급 함수와 람다 표현식의 관계입니다. 위 예제에서 name은 실제하는 값이 아니라, 그 값을 얻기 위한 (느긋한) 방법을 가리킵니다. 즉 name으로 데이터를 계산하는 로직이 담긴 두 줄 화살표 함수를 가리키는 것입니다. 함수형 프로그램은 이렇게 함수를 마치 값처럼 쓸 수 있습니다.
함수형 프로그래밍은 람다 표현식과 잘 어울리는 세 주요 고계함수 map, reduce, filter를 적극 사용할 것을 권장합니다. 사실 함수형 자바스크립트는 대부분 자료 리스트를 처리하는 코드 입니다. 함수형 배열 연산을 지원하는 array extras 함수는 ES5에도 있지만 필자는 이와 유사한 다른 유형의 연산까지 포괄하는 완전한 솔루션을 만들기 위해 로대시JS(lodashJS)라는 함수형 라이브러리를 쓰겠습니다. 로대시JS는 개발자가 함수형 프로그램을 작성하도록 유도하는 중요한 장치를 제공하고, 여러 가지 공통적인 프로그래밍 작업을 처리하는데 유용한 도우미 함수들을 풍성하게 지원합니다. 라이브러리 설치 후 전역 객체 _ (언더스코어 또는 로대시라고 읽음)를 통해 로대시JS 함수를 꺼내 쓰면 됩니다. 그럼 _.map()부터 시작합니다.
로대시JS 속 언더스코어
3.3.2 _.map: 데이터를 반환
덩치 큰 데이터 컬렉션의 원소를 모두 변환해야 할 때가 있습니다. 예를 들어 학생 리스트에서 각자의 성명을 추출한다고 합시다. 이런 코드를 다음과 같이 구현했던 적이 부지기수였겠죠?
1 | var result = []; |
map(collect라고도 합니다)은 배열 각 원소에 이터레이터 함수를 적용하여 크기가 같은 새 배열을 반환하는 고계함수입니다. _.map을 써서 함수형 스타일로 바꿔볼까요?
1 | _.map(persons, s => (s !== null && s !== undefined) ? s.fullname : ''); |
map연산을 수학적으로 쓰면 다음과 같습니다.1
2map(f, [e0, e1, e2...]) -> [r0, r1, r2...];
여기서 f(en) = rn
map 함수는 루프를 쓰거나 괴팍한 스코프 문제를 신경 쓸 필요 없이 컬렉션의 원소를 전부 파싱할 경우 아주 유용합니다. 항상 새로운 배열을 반환하므로 불변성도 간직되지요. map은 함수 f와 n개의 원소가 담긴 컬렉션을 받아 왼쪽 -> 오른쪽 방향으로 각 원소에 f를 적용한 계산 결과를, 역시 크기가 n인 새 배열에 담아 반환합니다. [그림 3-4]가 이 과정을 보여줍니다.
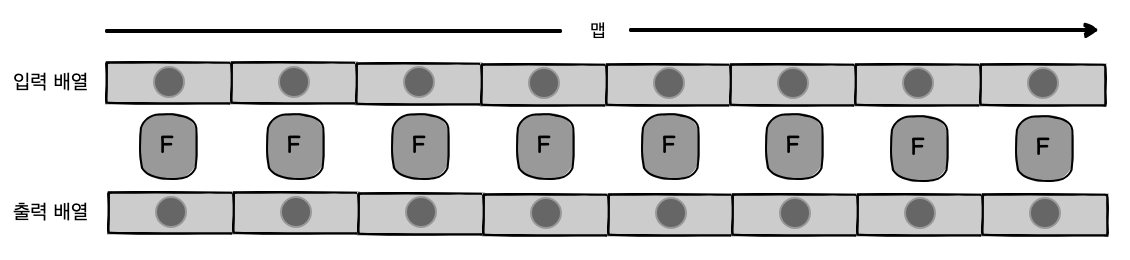 그림 3-4 연산은 배열 원소에 각각 이터레이터 함수 f를 실행한 결과값을 동일한 크기의 배열에 담아 반환합니다.
그림 3-4 연산은 배열 원소에 각각 이터레이터 함수 f를 실행한 결과값을 동일한 크기의 배열에 담아 반환합니다.예제에서 _.map은 배열을 반복하며 각 학생의 이름을 얻습니다. 이터레이터 함수는 일반적으로 람다 표현식으로 나타냅니다. 연산이 끝나면, 원본 배열은 건드리지 않은 채 다음 원소가 포함된 새 배열이 반환됩니다.1
['Haskell Curry', 'Barkley Rosser', 'John von Neumann', 'Alonzo Church']
추상화 내부를 알면 이해하는데 도움이 될 테니 _.map을 구현한 [코드 3-1]을 봅시다.1
2
3
4
5
6
7
8function map(arr, fn) {
const len = arr.length,
result = new Array(len);
for(let idx = 0; idx < len; idx++) {
result[idx] = fn(arr[idx], idx, arr);
}
return result;
}
위 코드를 보면 _.map도 안에서는 일반 루프를 씁니다. _.map이 반복을 대행하는 덕분에 개발자는 루프 변수를 하나씩 늘리며 경계 조건을 체크하는 등의 따분한 일은 이 함수에게 맡기고 이터레이터 함수에 구현한 비즈니스 로직만 신경쓰면 됩니다. 이렇듯 함수형 라이브러리를 쓰면 기존 코드도 진짜 순수 함수형 언어처럼 변신시킬 수 있습니다.
로대시JS는 일관성을 유지하기 위해 자바스크립트의 Array.reverse()에 해당하는 _.reverse() 메서드를 지원합니다. 이 함수는 원본 배열에 변이를 일으키므로 개발자는 부수효과가 언제 일어날지 알고 있어야 합니다.1
2
3_(persons).reverse().map(
p => (p != null && p != undefined) ? p.fullname : ''
);
못 보던 구문이 눈에 띄네요. 로대시JS는 기존 코드에 영향을 주지 않으면서도 쉽게 통합할 수 있는 멋진 방법을 제공합니다. 원하는 객체를 일단 _(…)로 감싸면 로대시JS의 강력한 함수형 도구를 이용해 마음껏 변환할 수 있습니다.
지금까지 데이터를 변환하는 함수를 적용해보았고, 다음은 새로운 자료구조에 기반을 둔 값으로 귀결시키는 reduce 함수를 살펴보겠습니다.
3.3.3 _.reduce: 결과를 수집
데이터를 변환한 후에는 변환된 데이터로부터 의미있는 결과를 도출하고 싶을때 reduce함수를 사용합니다.
reduce는 원소 배열을 하나의 값으로 짜내는 고계함수로, 원소마다 함수를 실행한 결과값의 누적치를 계산합니다. 그림으로 보면 이해가 더 빠릅니다.
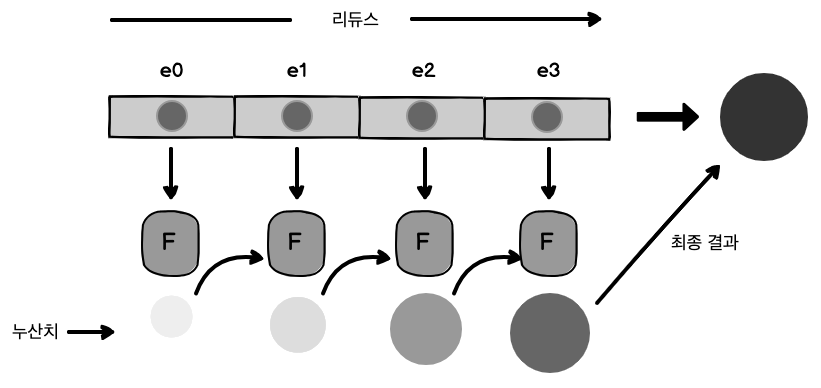 그림 3-5 배열을 단일 값으로 리듀스 하는 과정. 앞 단계의 결과값에 현 단계의 결과값을 누적하고 배열 끝에 이를 때까지 반복합니다. 반드시 하나의 값으로 귀결됩니다.
그림 3-5 배열을 단일 값으로 리듀스 하는 과정. 앞 단계의 결과값에 현 단계의 결과값을 누적하고 배열 끝에 이를 때까지 반복합니다. 반드시 하나의 값으로 귀결됩니다.[그림 3-5]를 수학적으로 쓰면 다음과 같습니다.1
reduce(f, [e0, e1, e2, e3]. accum) -> f(f(f(f(accum, e0), e1), e2), e3) -> R
[코드 3-2]는 reduce를 간단히 구현한 코드입니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14function reduce(arr, fn, accumulator) {
let idx = -1,
len = arr.length;
if(!accumulator && len > 0) { //누산치를 지정하지 않으면 배열의 첫번째 원소를 초기값으로 삼습니다.
accumulator = arr[++idx];
}
white (++idx < len) {
accumulator = fn(accumulator, arr[idx], arr); //배열을 반복하면서 원소마다 누산치, 현재 값, 인덱스, 배열을 인수로 fn을 실행합니다.
}
return accumulator; //단일 누산치를 반복합니다.
}
reduce는 다음 매개변수를 받습니다.
- fn : 배열 각 원소마다 실행할 이터레이터 함수로, 매개변수는 누산치, 현재 값, 인덱스, 배열입니다.
- accumulator : 계산할 초깃값으로 넘겨받는 인수이고, 함수 호출을 거치며 매 호출 시 계산된 결과값을 저장하는데 쓰입니다.
Person 객체 컬렉션에서 국가별 인구 등 유용한 통계치를 산출하는 프로그램을 작성해봅시다. 먼저 국가별 인구를 계산하는 코드입니다.
- javascript
1 | _(persons).reduce((stat, person) => { |
코드를 실행하면 주어진 Person 배열을 토대로 국가별 인구를 산출하여 다음과 같이 단일 객체에 담습니다.1
2
3
4
5{
'US' : 2,
'Greece' : 1,
'Hungary' : 1
}
많이 쓰이는 맵-리듀스 조합을 이용하면 작업을 더 단순화할 수 있습니다. 원하는 기능을 map, reduce 두 함수에 매개변수로 담아 보내고 이들을 연결해서 기능을 확장하는 겁니다. 대략 다음과 같은 흐름입니다.
1 | _(persons).map(func1).reduce(func2); |
여기서 원하는 작업을 func1, func2 함수에 각각 구현합니다. 다음 코드처럼 주요 흐름에서 함수를 떼어내 별도로 만드는 거죠.
- javascript
1 | const getCountry = person => person.address.country; |
map으로 객체 배열을 처리하여 국가 정보를 뽑아낸 다음, reduce로 최종 결과를 수집합니다. [코드 3-3]과 결과는 같지만, 훨씬 깔끔하고 확장 가능한 모양새입니다. 속성을 직접 건드리는 대신 (람다JS로) Person 객체의 address.city 속성에 초점을 맞춘 렌즈를 써봅시다.
1 | const cityPath = ['address', 'city']; |
거주 도시별 인구를 산출하는 작업도 마찬가지로 어렵지 않습니다.
1 | _(persons).map(R.view(cityLens)).reduce(gatherStats, {}); |
_.groupBy를 쓰면 코드가 훨씬 간명해 집니다.
1 | _.groupBy(persons, R.view(cityLens)); |
map과 달리 reduce는 누산치에 의존하기 때문에 결합법칙이 성립하지 않는 연산은 진행순서 (왼쪽 -> 오른쪽 또는 오른쪽 -> 왼쪽)에 따라 결과가 달라집니다. 나눗셈 같은 연산은 결과가 완전히 달라지죠.
_.reduceRight를 수학적으로 쓰면 다음과 같습니다.
1 | reduceRight(f, [e0, e1, e2], accum) -> f(e0, f(e1, f(e2, f(e3, accum)))) -> R |
_.divide로 나눗셈을 하는 다음 두 연산은 결과가 판이합니다.1
([1,3,4,5]).reduce(_.divide) !== ([1,3,4,5]).reduceRight(_.divide);
또 reduce는 일괄적용(apply-to-all) 연산이라서 배열을 순회하는 도중 그만두고 나머지 원소를 생략할 방법이 없습니다. 가령 어떤 입력값 리스트를 검증하는 경우, 검증 결과를 하나의 불리언 값으로 리듀스하면 입력값이 전부 올바른지 알아낼 수있을 것입니다.
하지만 reduce는 리스트 값을 빠짐없이 방문하기 때문에 다소 비효율적입니다. 잘못된 입력값이 하나라도 발견되면 나머지 값들은 더 이상 체크할 필요가 없으니까요. 앞으로 여러분이 애용하게 될 _.some, _.isUndefined, _.isNull 같은 함수를 써서 좀 더 효율적인 검증기를 만들어 보겠습니다. 각 원소에 _.some 함수를 실행하면 주어진 조건을 만족하는 값이 발견되는 즉시 true를 반환합니다.
1 | const isNotValid = val => _.isUndefined(val) || _.isNull(val); //undefined, null은 올바른 값이 아닙니다. |
notAllValid의 논리적 역함수 allValid는 주어진 술어가 모든 원소에 대해 true인지 _.every로 체크합니다.1
2
3
4
5const isValid = val => !_.isUndefined(val) && !_.isNull(val);
const allValid = args => _(args).every(isValid);
allValid(['string', 0, null]) //-> false
allValid(['string', 0, {}]) //-> true
map과 reduce는 배열 원소를 모두 탐색한다고 했습니다. 자료구조의 원소를 다 처리하지 않고 null이나 undefined인 객체는 건너뛰어야 할 경우도 있겠죠. 계산을 시작하기 전에 특정 원소는 미리 솎아낼 수단이 있으면 좋겠습니다. 바로 이런 일을 하는게 _.filter 입니다.
3.3.4 _.filter: 원하지 않는 원소를 제거
큰 데이터 컬렉션을 처리할 경우, 계산하지 않을 원소는 사전에 빼는게 좋습니다. 예컨대, 특정 년도 출생자나 유럽 거주자 인구만을 산출할 때, if-else 문을 남발하는 대신 _.filter를 쓰면 한결 코드가 깔끔해집니다.
filter(select라고도 합니다)는 배열 원소를 반복하면서 술어 함수 p가 true를 반환하는 원소만 추려내고 그 결과를 새 배열에 담아 반환하는 고계함수입니다. 수학적으로 쓰면 다음과 같습니다.
1 | filter(p, [d0, d1, d2, d3... dn]) -> [d0, d1,... dn] (원래 집합의 부분집합) |
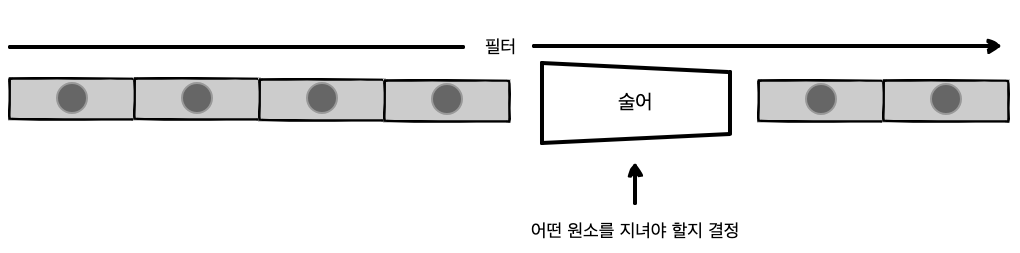 그림 3-6 필터는 주어진 배열 원소에 선별 기준을 나타내는 함수형 술어 p를 적용 후, 원래 배열의 부분집합을 돌려줍니다.
그림 3-6 필터는 주어진 배열 원소에 선별 기준을 나타내는 함수형 술어 p를 적용 후, 원래 배열의 부분집합을 돌려줍니다.[코드 3-5]는 filter 함수 구현부입니다.1
2
3
4
5
6
7
8
9
10
11
12function filter(arr, predicate) {
let idx = -1,
len = arr.length,
result = [];
while(++idx < len) {
let value = arr[idx];
if(predicate(value, idx, this)) {
result.push(value);
}
}
return result;
}
filter는 대상 배열과, 원소를 결과에 포함할지 결정하는 술어 함수 두 가지를 인수로 받습니다. 술어 함수 결과가 true인 원소는 남기고 그렇지 않은 원소는 내보냅니다. filter는 배열에서 오류 데이터를 제거하는 용도로 자주쓰입니다.1
_(persons).filter(isValid).map(fullname);
filter의 용도는 이뿐만이 아닙니다. Person 객체 컬렉션에서 1903년 출생자들만 추리고자 할 때, 조건문 대신 _.filter를 쓰면 코드가 훨씬 간결해집니다.1
2
3const bornIn1903 = person => person.birthYear === 1903;
_(persons).filter(bornIn1903).map(fullname).join(' and ');
//-> 'John von Neumann and Alonzo Church'
배열 축약
지금까지 실펴본 것처럼, 확장성 좋고 강력한 함수를 이용해서 코딩하면 코드가 깔끔해질 뿐만 아니라 데이터를 더 잘 이해할 수 있습니다. 선언적 스타일은 개발자가 문제의 해법에 어떻게 도달해야 하는지 고민하기보다 애플리케이션이 어떤 결과를 내야 하는지에 전념하게 합니다. 따라서 애플리케이션을 더 깊이 있게 헤아리는 데 큰 도움이 됩니다.
3.4 코드 헤아리기
‘코드를 헤아린다(reason)’ 는 건 무슨 뜻일까요? 1, 2장에서 필자는 프로그램의 일부만 들여다봐도 무슨 일을 하는 코드인지 멘털모델을 쉽게 구축할 수 있다는 의미로 이 표현을 사용했습니다. 여기서 멘털모델이란 전체 변수의 상태와 함수 출력 같은 동적인 부분뿐만 아니라, 설계 가독성 및 표현성 같은 정적인 측면까지 포괄하는 개념입니다. 두 가지 모두 중요합니다. 여러분은 이 책을 읽으며 불변성과 순수함수가 이러한 멘털 모델 구축을 더 용이하게 해준다는 사실을 깨닫게 될 것입니다.
앞서 필자는 고수준 연산을 서로 연결하여 프로그램을 구축하는 것이 중요하다고 강조했습니다. 명령형 프로그램은 흐름 자체가 함수형 프로그램과 근본적으로 다릅니다. 함수형 흐름은 프로그램 로직을 파헤치지 않아도 뭘 하는 프로그램인지 윤곽을 잡기 쉽기 때문에, 개발자는 코드뿐만 아니라 결과를 내기 위해 서로 다른 단계를 드나드는 흐름까지 더 깊이 헤아릴 수 있습니다.
3.4.1 선언적 코드와 느긋한 함수 체인
FP의 선언적 모델에 따르면, 프로그램이란 개별적인 순수함수들을 평가하는 과정이라 볼 수 있습니다. 그래서 필요 시 코드의 흐름성과 표현성을 높이기 위한 추상화 수단을 지원하며, 이렇게 함으로써 여러분이 개발하려는 애플리케이션의 실체를 명확하게 표현하는 온톨로지(ontology) 또는 어휘집(vocabulary)을 만들 수 있습니다. map, reduce, filter라는 구성 요소를 바탕으로 순수함수를 쌓아가면 자연스레 한눈에 봐도 흐름이 읽히는 코드가 완성됩니다.
이 정도 수준으로 추상화하면 비로소 기반 자료구조에 영향을 끼치지 않는 방향으로 연산을 바라볼 수 있습니다. 이론적으로 말해서 배열, 연결 리스트, 이진 트리 등 어떤 자료구조를 쓰더라도 프로그램 자체의 의미가 달라져선 안 됩니다. 그래서 FP는 자료구조보다 연산에 더 중점을 둡니다.
이름 리스트를 읽고 데이터를 정제 후, 중복은 제거하고 정렬하는 일련의 작업을 예로 들어봅시다. 명령형 버전으로 먼저 프로그램을 작성 후, 함수형으로 리펙터링 하겠습니다.1
var names = ['alonzo church', 'Haskell curry', 'stephen_kleene', 'John Von Neumann', 'stephen_kleene'];
[코드 3-6]은 명령형 프로그램입니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var result = [];
fot (let i=0; i < names.length; i++) { //배열의 원소(이름)를 모두 순회합니다.
var n = names[i];
if(n !== undefined && n !== null){ //올바른 이름인지 조사합니다.
var ns = n.replace(/_/, ' ').split(' '); //데이터 형식이 제각각일 수 있으니 정규화(정정) 단계가 필요합니다.
for(let j=0; j < ns.length; j++) {
var p = ns[j];
p = p.charAt(0).toUpperCase() + p.slice(1);
ns[j] = p;
}
if(result.indexOf(ns.join(' ')) < 0) { //result에 같은 이름이 있는지 보고 중복을 제거합니다.
result.push(ns.join(' '))
}
}
}
result.sort(); //배열을 정렬합니다.
결과는 제대로 나옵니다.1
['Alonzo Church', 'Haskell Curry', 'John Von Neumann', 'Stephen Kleene']
명령형 코드의 단점은 특정 문제의 해결만을 목표한다는 점입니다. [코드 3-6]역시 함수형보다 훨씬 저수준에서 추상한 코드로서 한 가지 용도로 고정됩니다. 추상화 수준이 낮을수록 코드를 재사용할 기회는 줄어들고 에러 가능성과 코드 복잡성은 증가합니다.
반면, FP는 블랙박스 컴포넌트를 서로 연결만 해주고, 뒷일은 테스트까지 마친 검증된 API에게 모두 맡깁니다. 폭포수 떨어지듯 함수를 연달아 호출하는 모습이 눈에 더 잘 들어오지 않나요?1
2
3
4
5
6
7
8_.chain(names) //함수 체인을 초기화합니다.
.filter(isValid) //잘못된 값은 제거합니다.
.map(s => s.replace(/_/, ' ')) //값을 정규화합니다.
.uniq() //중복을 솎아냅니다.
.map(_.startCase) //대소문자를 맞춥니다.
.sort()
.value();
// -> ['Alonzo Church', 'Haskell Curry', 'John Von Neumann', 'Stephen Kleene']
names 배열을 정확한 인덱스로 순회하는 등 버거운 일은 모두 _.filter와 _.map함수가 대행하므로 여러분은 그저 나머지 단계에 대한 프로그램 로직을 구현하면 됩니다. _.uniq로 중복 데이터를 집어내고, _.startCase로 각 단어의 첫자를 대문자로 바꾼 다음, 마지막에 알파벳 순으로 정렬을 합니다.
필자는 기왕이면 [코드 3-7] 같은 프로그램이 낫다고 봅니다. 여러분도 그런가요? 코딩 작업도 확연히 줄지만 단순 명료한 구조가 아주 매력적이네요.
Person 객체 배열에서 국가별 인구를 계산했던 [코드 3-4]로 돌아가 gatherStats 함수를 조금 보완합시다.1
2
3
4
5
6
7const gatherStats = function(stat, country) {
if(!isValid(stat[country])) {
stat[country]= {'name' : country, 'count': 0};
}
stat[country].count++;
return stat;
}
이제 다음과 같은 구조를 지닌 객체가 반환되겠죠,1
2
3
4
5{
'US' : {'name': 'US', count: 2},
'Greece' : {'name': 'Greece', count: 1},
'Hungary' : {'name': 'Hungary', count: 1}
}
이 객체에서 국가별 데이터는 반드시 하나뿐입니다. 재미삼아 Person 배열에 데이터를 몇 개 더 넣어볼까요?1
2
3
4
5
6
7
8
9
10
11const p5 = new Person('David', 'Hilbert', '555-55-5555');
p5.address = new Address('Germany');
p5.birthYear = 1903;
const p6 = new Person('Alan', 'Turing', '666-66-6666');
p6.address = new Address('England');
p6.birthYear = 1912;
const p7 = new Person('Stephen', 'Kleene', '777-77-7777');
p7.address = new Address('US');
p7.birthYear = 1909;
다음은 인구가 가장 많은 국가를 반환하는 프로그램입니다. 이번에도 여러 함수형 장치들을 _.chain() 함수로 연결하겠습니다.1
2
3
4
5
6
7
8
9
10_.chain(persons) //느긋한 함수체인을 만들어 주어진 배열을 처리합니다.
.filter(isValid)
.map(_.property('address.country')) //Person 객체의 address.country 속성을 _.property로 얻습니다. _.property는 람다JS의 R.view()와 거의 같은 로대시JS 함수입니다.
.reduce(gatherStats, {})
.values()
.sortBy('count')
.reverse()
.first()
.value() //체인에 연결된 함수를 모두 실행합니다.
.name; //'US'
_.chain 함수는 주어진 입력을 출력으로 변환하는 연산들을 연결함으로써 입력 객체의 상태를 확장합니다. _(…) 객체로 단축 표기한 구문과 달리, 이 함수는 임의의 함수를 명시적으로 체이닝 가능한 함수로 만듭니다.
_.chain을 쓰면 복잡한 프로그램을 느긋하게 작동시키는 장점도 있습니다. 제일 끝에서 value() 함수를 호출하기 전에는 아무것도 실행되지 않으니까요. 결과값이 필요 없는 함수는 실행을 건너뛸 수 있어서 애플리케이션 성능에 엄청난 영향을 미칩니다. [그림 3-7]은 이 프로그램의 제어 흐름을 나타낸 것 입니다.
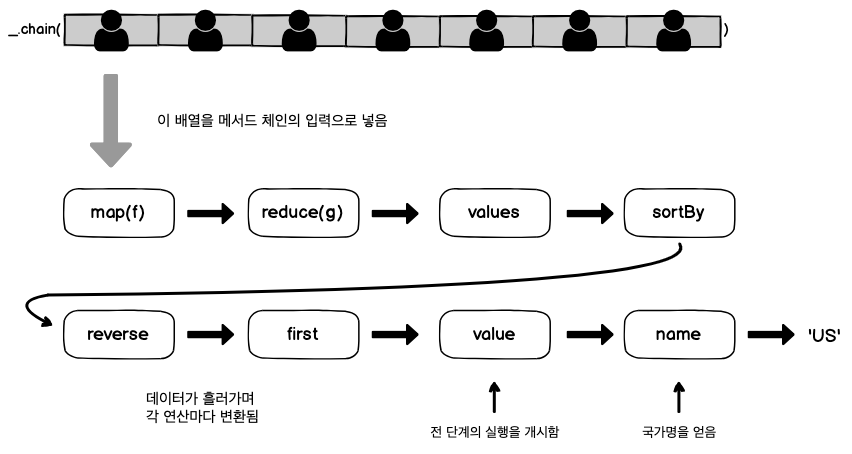 로대시JS 함수를 체이닝하여 구성한 프로그램 제어구조. Person 객체 배열은 각 연산을 차례로 지나면서 처리되고 결국 하나의 값으로 변환됩니다.
로대시JS 함수를 체이닝하여 구성한 프로그램 제어구조. Person 객체 배열은 각 연산을 차례로 지나면서 처리되고 결국 하나의 값으로 변환됩니다.이제 함수형 프로그램이 왜 우월한지 감이 오나요? 명령형으로 작성했다면 어떤 코드가 됐을지 한번 상상해보세요. [코드 3-8]이 부드럽게 작동하는 건 FP의 근본 원리인, 부수효과 없는 순수함수 덕분입니다. 체인에 속한 각 함수는 이전 단계의 함수가 제공한 새 배열에 자신의 불변 연산을 적용합니다. _.chain()으로 시작하는 이런 로대시JS의 패턴은 거의 모든 요구를 충족하는 맥가이버 칼을 제공합니다. 이런 방식은 함수형 프로그래밍의 독특한 무인수(point-free) 프로그래밍 스타일로 이어지는데요, 자세한 얘기는 다음 장 도입부에서 소개합니다.
3.4.2 유사 SQL 데이터: 데이터로서의 함수
지금까지 map, reduce, filter, groupBy, sortBy, uniq 등의 함수를 살펴봤는데요, 이름을 잘 보면 그 어휘만으로도 함수가 데이터에 하는 일이 무엇인지 어렵잖게 추론할 수 있습니다. 그런데 관점을 조금만 틀어보면 이 함수들이 SQL 구문을 쏙 빼 닮았다는 사실을 알 수 있습니다. 이는 우연이 아닙니다.
개발자 대부분 SQL에 익숙한 편이라 쿼리만 봐도 데이터에 무슨 작업을 하는지 압니다. 예를 들어 Person 객체 컬렉션은 [표 3-1]처럼 나타낼 수 있습니다.
표 3-1 테이블로 표현한 Person 리스트
| ID | 이름 | 성 | 국적 | 생년 |
|---|---|---|---|---|
| 0 | Haskell | Curry | US | 1900 |
| 1 | Barkley | Rosser | Greece | 1907 |
| 2 | John | Von Neumann | Hungary | 1903 |
| 3 | Alonzo | Church | US | 1903 |
| 4 | David | Hilbert | Germany | 1862 |
| 5 | Alan | Turing | England | 1912 |
| 6 | Stephen | Kleene | US | 1909 |
결국 쿼리 언어를 구사하듯 개발하는 것과 함수형 프로그래밍에서 배열에 연산을 적용하는 것은 일맥상통합니다. 함수형 프로그램은 흔히 사용되는 어휘집이나 대수학 개념을 활용해서 데이터 자체의 성격과 구조 체계를 더 깊이 추론할 수 있게 도움을 줍니다.1
2
3SELECT p.firstname FROM Person p
WHERE p.birthYear > 1903 and p.country IS NOT 'US'
GROUP BY p.firstname
위 쿼리는 실행 결과가 어떤 데이터가 나올지 불 보듯 훤합니다. 자바스크립트 버전의 프로그램으로 전환하기 전에 몇 가지 함수 별칭을 세팅해서 요점을 분명히 하겠습니다. 로대시JS가 지원하는 믹스인(mixin)(섞어 넣기) 기능을 응용하면, 핵심 라이브러리에 함수를 추가하여 확장한 후 마치 원래 있던 함수처럼 체이닝 할 수 있습니다.
1 | _.mixin({'select' : _.map, |
이렇게 만든 믹스인 객체는 다음 프로그램처럼 적용 할 수 있습니다.
- javascript
1 | _.from(persons) |
SQL 키워드와 동일한 별칭으로 기능을 매핑해서 함수형 코드를 쿼리 언어와 최대한 유사하게 작성해봤습니다.
자. 이제 함수형 프로그래밍이 명령형 코드 위에 강력한 추상화를 제공한다는 믿음이 생겼으리라 봅니다. 데이터를 처리하고 파싱하는 데 쿼리 언어보다 더 좋은 방법이 있을까요? 자바스크립트 코드도 SQL처럼 데이터를 함수 형태로 모형화 할 수 있는데, 이를 데이터로서의 함수(functions as data)라는 개념으로 부르기도 합니다. 선언적으로 어떤 데이터가 출력되어야 할지 서술할 뿐 그 출력을 어떻게 얻는지는 논하지 않지요. 필자는 이번 장에서 루프문을 전혀 쓸 필요가 없었고, 앞으로도 루프를 쓰지 않으려고 합니다. 고수준의 추상화로 루프를 대체할 수 있으니까요.
재귀 역시 루프를 대체할 때 많이 쓰는 기법입니다. 천성이 자기 반복적(self-similar)인 문제에 대해 반복 자체를 재귀로 추상하여 푸는 방법이지요. 이런 유형의 문제는 순차적 함수 체인만으로는 해결하기 어렵고 비효율적입니다. 하지만 재귀는 일반 루프로 수행하는 버거운 작업을 언어 자체의 런타임에 맡김으로써 독자적인 방식으로 데이터를 처리합니다.
3.5 재귀적 사고방식
좀처럼 머릿속에 해법이 떠오르지 않는 어렵고 복잡한 문제들이 있습니다. 이럴 땐 바로 문제를 분해할 방법을 찾아야 합니다. 전체 문제를 더 작은 분신들로 쪼갤 수 있다면 작은 문제들을 하나씩 풀면서 전체 문제도 풀 수 있을 것 입니다.
자바스크립트에서 XML 파일, HTML 문서, 그래프 등을 파싱할 때 재귀를 다양하게 활용합니다. 이 절에서는 재귀가 무엇인지, 그리고 재귀적으로 생각하는 방법을 예제와 함께 설명하고, 재귀를 이용해 몇몇 자료구조를 파싱하는 예제를 함께 살펴보겠습니다.
3.5.1 재귀란?
재귀(recusion)는 주어진 문제를 자기 반복적인 문제들로 잘게 분해한 다음, 이들을 다시 조합해 원래 문제의 정답을 찾는기법입니다. 재귀 함수의 주된 구성 요소는 다음과 같습니다.
- 기저 케이스(base case, 종료 조건:terminating condition이라고도 합니다)
- 재귀 케이스(recursive case)
기저 케이스는 재귀 함수가 구체적인 결과값을 바로 계산할 수 있는 입력 집합입니다. 재귀 케이스는 함수가 자신을 호출할 때 전달한 입력 집합(최초 입력 집합보다 점점 작아집니다)을 처리합니다. 입력 집합이 점점 작아지지 않으면 재귀가 무한 반복되며 결국 프로그램이 뻗겠죠. 함수가 반복될수록 입력 집합은 무조건 작아지며, 제일 마지막에 기저 케이스로 빠지면 하나씩 값으로 귀결됩니다.
3.5.2 재귀적으로 생각하기
재귀적 사고란, 자기 자신 또는 그 자신을 변형한 버전을 생각하는 겁니다. 재귀적 객체는 스스로를 정의합니다. 가령 트리 구조에서 가지(branch)를 합성한다고 합시다. 어떤 가지는 다른 가지처럼 잎(leaf)이 붙어 있고, 이 잎에는 또다른 잎과 가지가 주렁주렁 달려 있겟죠. 이런 프로세스가 끝없이 이어지다가 어떤 외부적인 한정 요소(트리의 전체 크기)에 이르면 멈출 것입니다.
자, 그럼 준비운동 겸 숫자 배열의 원소를 모두 더하는 간단한 예제를 봅시다. 우선 명령형 버전으로 구현한 다음 점점 함수형으로 고쳐보겠습니다.1
2
3
4var acc = 0;
for(let i=0; i < nums.length; i++) {
acc += nums[i];
}
그리고 중간에 합계를 어딘가 보관하기 위해 누산치가 필요하다는 강박증에 사로잡혀 있겠죠. 하지만 수동 루프가 정말 필요할까요? 이미 여러분 손에는 당장 꺼내 쓸 수 있는 함수형 무기 (_.reduce)가 있습니다.1
_(nums).reduce((acc, current) => acc + current, 0);
수동 반복 코드를 프레임워크에 밀어 넣어 애플리케이션 코드로부터 추상하는 방법도 있지만, 반복하는 작업 자체를 일임할 수 있다면 더 좋겠지요? _.reduce 함수를 쓰면 루프는 물론 리스트 크기조차 신경 쓸 필요가 없습니다. 첫 번째 원소를 나머지 원소들과 순차적으로 더해가며 결과값을 계산하는 재귀적 사고방식을 적용하는 셈이죠. 이 사고방식을 확장하면 결국 다음과 같이 수평사고(lateral thinking)라고 불리는 일련의 연산을 수행하는 과정으로 덧셈을 바라보게 됩니다.1
2
3sum[1,2,3,4,5,6,7,8,9] = 1 + sum[2,3,4,5,6,7,8,9]
= 1 + 2 + sum[3,4,5,6,7,8,9]
= 1 + 2 + 3 + sum[4,5,6,7,8,9]
재귀의 반복은 동전의 앞/뒷면입니다. 재귀는 변이가 없으므로, 더 강력하고 우수하며 표현적인 방식으로 반복을 대체할 수 있습니다. 사실상 순수 함수형 언어는 모든 루프를 재귀로 수행하기 때문에 do, for, while 같은 기본 루프 체계조차 없으며, 재귀를 적용한 코드가 더 이해하기 쉽습니다. 점점 줄어드는 입력 집합에 똑같은 작업을 여러 번 반복한다는 전헤하에 작동하기 때문입니다. [코드 3-10]의 재귀 코드는 로대시JS의 _.first, _.rest 함수로 각각 배열 첫 번째 원소와 그 나머지 원소들에 접근합니다.1
2
3
4
5
6
7
8function sum(arr) {
if(_.isEmpty(arr)) {
return 0;
}
return _.first(arr) + sum(_.rest(arr)); //재귀 케이스 : _.first와 _.rest로 입력을 점점 줄여가며 자신을 호출합니다.
}
sum([]); //-> 0
sum([1,2,3,4,5,6,7,8,9]); //-> 45
더하려는 배열이 빈 배열일 경우 기저 케이스로서 이때는 당연히 0을 반환합니다. 이외에 원소가 포함된 배열은 첫 번째 원소를 추출 후 두 번째 이후 원소들과 계속 재귀적으로 더합니다. 이때 내부적으로 재귀 호출 스택이 겹겹이 쌓입니다. 알고리즘이 종료 조건에 이르면 쌓인 스택이 런타임에 의해 즉시 풀리면서 모두 실행되고 이 과정에서 실제 덧셈이 이루어 집니다. 바로 이런식으로 재귀를 이용해 언어 런타임에 루프를 맡기는 것입니다. 다음은 이러한 덧셈 알고리즘을 단계별로 나누어 표시한 것입니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
191 + sum[2,3,4,5,6,7,8,9]
1 + 2 + sum[3,4,5,6,7,8,9]
1 + 2 + 3 + sum[4,5,6,7,8,9]
1 + 2 + 3 + 4 + sum[5,6,7,8,9]
1 + 2 + 3 + 4 + 5 + sum[6,7,8,9]
1 + 2 + 3 + 4 + 5 + 6 + sum[7,8,9]
1 + 2 + 3 + 4 + 5 + 6 + 7 + sum[8,9]
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + sum[9]
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + sum[]
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 0 // -> 여기서 정지, 이제 스텍이 풀립니다.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9
1 + 2 + 3 + 4 + 5 + 6 + 7 + 17
1 + 2 + 3 + 4 + 5 + 6 + 24
1 + 2 + 3 + 4 + 5 + 30
1 + 2 + 3 + 4 + 35
1 + 2 + 3 + 39
1 + 2 + 42
1 + 44
45
재귀와 수동 반복, 성능은 어떨까요? 지난 세월 동안 컴파일러는 아주 영리하게 루프를 최적화 할 수 있도록 진화했습니다. ES6 부터는 꼬리 호출 최적화(tail-call optimization)까지 추가되어 사실상 재귀와 수동 반복의 성능 차이는 미미해졌지요. 다음은 sum 함수를 조금 다른 방법으로 구현한 코드입니다.
1 | function sum(arr, acc = 0) { |
함수 본체의 가장 마지막 단계, 즉 꼬리 위치(tail position)에서 재귀 호출을 합니다. 이렇게 하면 어떤 이점이 있는지는 7장에서 함수형 최적화를 이야기하며 다시 살펴보겠습니다.
3.5.3 재귀적으로 정의한 자료구조
지금까지 Person 객체의 샘플 데이터로 입력한 이름들이 대체 누굴까 궁금하게 생각한 독자도 있을 겁니다. 1900년대는 함수형 프로그래밍의 원조를 이룬 수학 분파(람다 대수학, 범주론등)의 활동이 왕성했었죠.
이 시기에 출간된 자료는 대부분 알론조 처치(Alonzo Church) 교수가 이끄는 몇몇 대학 교수들이 집대성한 식견과 정리에 근거합니다. 바클리 로서(Barkley Rosser), 엘런 튜링(Alan Turing), 스티븐 클리니(Stephen Kleene)같은 수학자들이 바로 처치 교수의 박사 학위 지도를 받은 학생들이었죠. [그림 3-8]은 이 사제 관계를 그래프로 나타낸 것입니다.
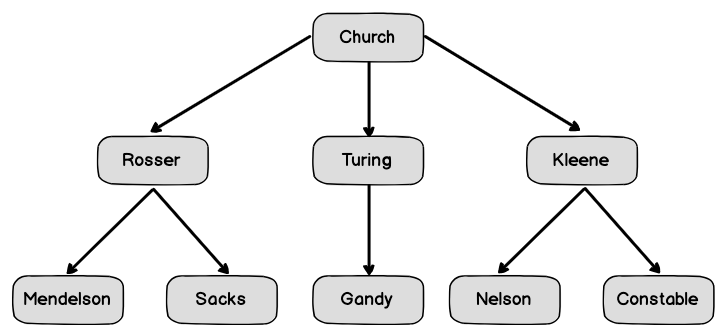 그림 3-8 함수형 프로그래밍에 지대한 공헌을 한 수학자들. 트리에서 부모 -> 자식 방향으로 연결된 화살표가 '~의 학생'이라는 관계를 뜻합니다.
그림 3-8 함수형 프로그래밍에 지대한 공헌을 한 수학자들. 트리에서 부모 -> 자식 방향으로 연결된 화살표가 '~의 학생'이라는 관계를 뜻합니다.트리는 XML 문서, 파일 시스템, 분류학, 범주, 메뉴 위젯, 패시 내비게이션, 소셜 그래프 등 다양한 분야에 쓰이는 아주 일반적인 자료구조로서 처리 방법을 잘 알아둘 필요가 있습니다. [그림 3-8]을 잘 보면 여러 노드(node)가 사제 관계를 나타내는 간선(edge: 화살표)으로 연결되어 있습니다. 배열처럼 평탄한 자료구조를 파싱할 때 쓰는 함수형 기법은 이런 트리 구조의 데이터에는 적절하지 않습니다. 자바스크립트 언어 자체로 내장 트리 객체를 지원하지는 않으므로 노드 기반의 단순한 자료구조를 만들어야 합니다. 노드는 값을 지닌 객체로 자신의 부모와 자식 배열을 레퍼런스로 참조합니다. [그림 3-8]에서 Rosser는 Church를 부모 노드로, Mendelson과 Sacks는 자식 노드로 가리킵니다. Church처럼 부모가 없는 노드가 루트입니다. 다음은 Node 형을 정의한 코드입니다.
- javascript
1 | class Node { |
노드는 이렇게 생성합니다.
1 | const church = new Node(new Person('Alonzo', 'Church', '111-11-1111')); //이를 트리에 있는 모든 노드마다 반복합니다. |
트리(tree)는 루트 노드가 포함된 재귀적인 자료구조 입니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Tree {
constructor(root) {
this._root = root;
}
static map(node, fn, tree = null) { //이 메서드보다 더 많이 쓰이는 Array.prototype.map과 혼동하지 않게 정적 메서드로 합니다. 정적 메서드는 사실상 독립형 함수로 쓸 수 있습니다.
node.value = fn(node.value); //이터레이터 함수를 실행하여 트리의 노드값을 업데이트 합니다.
if(tree === null) {
tree = new Tree(node); //Array.prototype.map과 비슷합니다. 새로운 트리를 만듭니다.
}
if(node.hasChildren()) { //자식이 없는 노드는 계속할 필요가 없습니다(기저 케이스)
_.map(node.children, function(child) { //각 자식 노드에 주어진 함수를 실행합니다.
Tree.map(child, fn, tree) //각 자식 노드를 재귀 호출 합니다.
})
}
return tree;
}
get root() {
return this._root;
}
}
노드의 메인 로직은 append 메서드에 있습니다. 한 노드에 자식을 덧붙일 때 그 자식 노드의 부모 레퍼런스가 이 노드를 가리키게 하고 이 자식 노드를 자식 리스트에 추가합니다. 다음과 같은 식으로 루트부터 시작해 다른 자식 노드들과 연결하면 트리가 완성됩니다.1
2
3
4church.append(rosser).append(turing).append(kleene);
kleene.append(nelson).append(constable);
rosser.append(mendelson).append(sacks);
turing.append(gandy)
각 노드는 Person 객체를 감쌉니다. 재귀 알고리즘은 루트서부터 모든 자식 노드를 타고 내려가면서 전체 트리를 전위 순회(preorder traversal) 합니다. 자기 반복적인 재귀 특성 때문에 순회를 루트에서 시작하든, 임의의 노드에서 시작하든 똑같습니다. 그래서 Array.prototype.map과 하는 일이 비슷한 고계함수 Tree.map을 쓰는 건데요, 이 함수는 각 노드 값을 평가할 함수를 받습니다. 보다시피 이 데이터를 모형화한 자료구조(여기선 트리)와 무관하게 이 함수의 의미는 변함 없습니다. 사실상 어떤 자료형이라도 그 구조를 유지한 채 매핑할 수 있지요. 이렇게 구조를 유지한 상태에서 함수를 자료형에 매핑하는 함수 개념을 5장에서 더 자세히 이야기 할 것입니다.
루트 노드에서 출발한 전위 순회는 다음 과정을 거칩니다.
- 루트원소의 데이터를 표시합니다.
- 전위 함수를 재귀 호출하여 왼쪽 하위 트리를 탐색합니다.
- 같은 방법으로 오른쪽 하위 트리를 탐색합니다.
[그림 3-9]는 이 알고리즘이 지나가는 경로입니다.
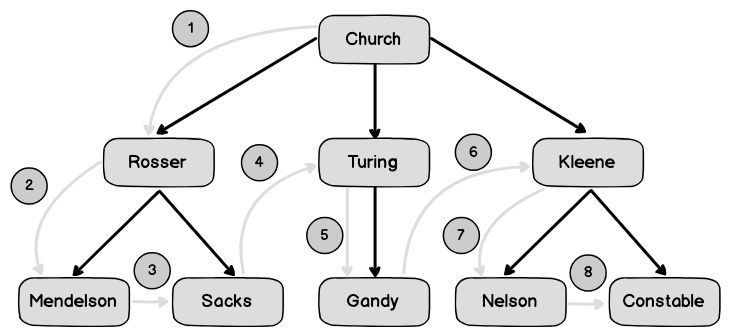 그림 3-9 재귀적 전위 순회경로. 루트에서 출발해 왼쪽에서 오른쪽 방향으로 자식 노드를 훑고 내려갑니다.
그림 3-9 재귀적 전위 순회경로. 루트에서 출발해 왼쪽에서 오른쪽 방향으로 자식 노드를 훑고 내려갑니다.Tree.map 함수는 루트노드(기본적으로, 트리의 시작 지점) 및 각 노드 값을 변환하는 이터레이터 함수를 필수로 밭습니다.1
Tree.map(church, p => p.fullname);
트리를 전위 순회하면서 해당 함수를 각 노드에 실행하면 다음 결과가 나옵니다.1
'Alonzo Church', 'Barkley Rosser', 'Ellot Mendelson', 'Gerald Sacks', 'Alan Turing', 'Robin Gandy', 'Stephen Kleene', 'Nels Nelson', 'Robert Constable',
변이 및 부수효과 없는 자료형을 다룰 때 데이터 자체를 캡술화하여 데이터에 접근하는 방법을 통제하는 것이 함수형 프로그래밍의 관건입니다. 자료구조 파싱은 소프트웨어에서 가장 기본적인 작업이자, 함수형 프로그래밍의 주특기이기도 합니다. 이 장에서는 함수형 확장 라이브러리 로대시JS와 이의 바탕이 되는 자바스크립트 함수형개발 스타일에 관하여 자세히 알아보았습니다. 함수형 프로그래밍은 원하는 결과를 얻기 위한 비즈니스 로직이 담겨 있는 고수준의 연산을 일련의 단계들로 체이닝하는, 간결한 흐름 중심의 모델을 선호합니다.
이처럼 흐름 중심으로 코딩하면 재사용성, 모듈화 측면에서도 당연히 유익한데요, 이 장에서 필자는 아주 대략적으로만 살펴보았습니다. 4장에서는 흐름 중심의 프로그래밍 사상을 한 수준 더 발전시켜 진짜 함수 파이프라인을 구축하는 문제를 집중적으로 논합니다.
3.6 마치며
- 고계함수 map, reduce, filter를 쓰면 코드를 확장할 수 있습니다.
- 로대시JS는 데이터 흐름과 변환 과정이 명확히 구획된 제어 체인을 통해 데이터 처리 및 프로그램 작성을 도모합니다.
- 함수형 프로그래밍의 선언적 스타일로 개발하면 코드를 헤아리기 쉽습니다.
- 고수준의 추상화를 SQL 어휘로 매핑하면 더 심도있게 데이터를 이해할 수 있습니다.
- 재귀는 자기 반복적 문제를 해결하는 데 쓰이며, 정의된 자료구조를 재귀적으로 파싱해야 합니다.